
前言
最近有做相关汉字转拼音处理,因此了解一下,摘抄于此,方便查阅。
好记性不如烂笔头
正文
虽然不常用,了解一下。
基本汉字有20902字。
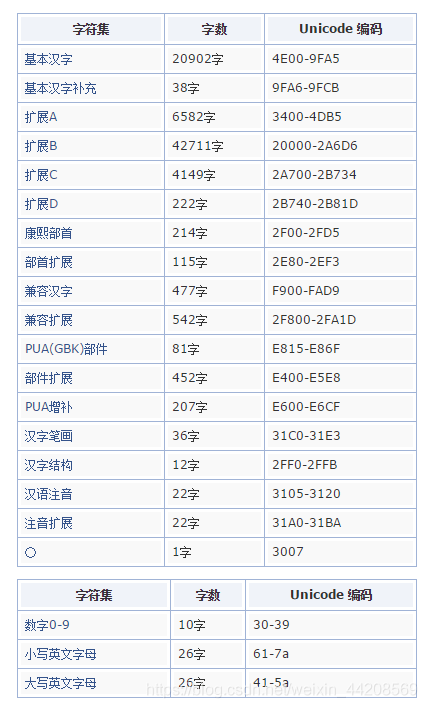
相关汉字编码介绍
GB2312编码
1981年5月1日发布的简体中文汉字编码国家标准。GB2312对汉字采用双字节编码,收录7445个图形字符,其中包括6763个汉字。
BIG5编码
台湾地区繁体中文标准字符集,采用双字节编码,共收录13053个中文字,1984年实施。
GBK编码
1995年12月发布的汉字编码国家标准,是对GB2312编码的扩充,对汉字采用双字节编码。GBK字符集共收录21003个汉字,包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。
GB18030编码
2000年3月17日发布的汉字编码国家标准,是对GBK编码的扩充,覆盖中文、日文、朝鲜语和中国少数民族文字,其中收录27484个汉字。GB18030字符集采用单字节、双字节和四字节三种方式对字符编码。兼容GBK和GB2312字符集。
Unicode编码
国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
简体字范围
4E00-9FA5
简体和繁体字范围
4E00-9FFF
判断简体和繁体的范围
Java代码片段
public static String REGEXP_SIMPLIFIED = "^[\u4E00-\u9FA5]+$";
public static String REGEXP_SIMPLIFIED_TRADITIONAL = "^[\u4E00-\u9FFF]+$";
public static boolean matcher(String str, String regex) {
return Pattern.compile(regex).matcher(str).find();
}
HanZiUtils.matcher("体", HanZiUtils.REGEXP_SIMPLIFIED);
HanZiUtils.matcher("體", HanZiUtils.REGEXP_SIMPLIFIED_TRADITIONAL);
参考文章
© 版权声明
