
前言
在开发中,对于字节序的大端序和小端序有时候容易忘记,这里简单记录一下相关内容,方便自己回顾和查询。
参考文1有图展示,推荐看那篇文章哈,多谢。
正文
现代计算机系统中含有两种存放数据的字节序:大端序(Big-endian)和小端序(Little-endian)。
字节序
字节序,又称端序,简单点说,就是字节的存储顺序。
字节顺序是指占内存多于一个字节类型的数据在内存中的存放顺序,通常有小端序、大端序两种字节顺序。
字节的高位和低位
举个例子,十六进制变量a的值。
int a = 0x04030201 字节 高位 <----- 低位 十六进制 04 03 02 01
字节的高低是相对的,比如,02相对01是高位,但相对于03或04是低位。
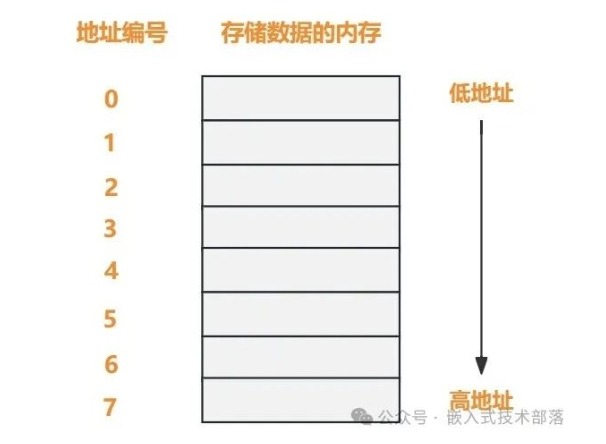
地址的高位和低位
地址编号小的是低地址,地址编号大的是高地址。
读数据永远是从低地址开始的!!!
小端序和大端序
高位<-->低位 0x04030201
小端字节序
Little-endian,小端字节序。
低字节存于内存低地址,高字节存于内存高地址。
重点:
低字节 ——> 内存低地址
高字节 ——> 内存高地址
以0x04030201为例。
字节的高位和低位
[字节] 高位 <----- 低位 十六进制 04 03 02 01
内存的高位和低位
[内存] 低地址 ------> 高地址 [ 地址1 ][ 地址2 ][ 地址3 ][ 地址1 ]
以0x04030201在小端序中内存为例
[内存] 低地址 ------> 高地址 [ 地址1 ][ 地址2 ][ 地址3 ][ 地址1 ] [ 01 ][ 02 ][ 03 ][ 04 ]
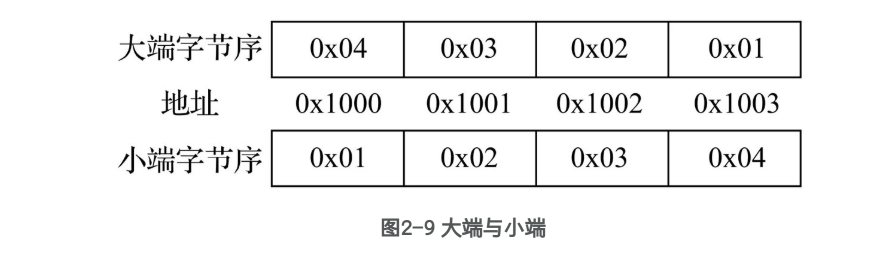
大端字节序
Big-endian,大端字节序,高字节存于内存低地址,低字节存于内存高地址。
重点:
高字节 ——> 内存低地址
低字节 ——> 内存高地址
还是以0x04030201在小端序中内存为例
[内存] 低地址 ------> 高地址 [ 地址1 ][ 地址2 ][ 地址3 ][ 地址4 ] [ 04 ][ 03 ][ 02 ][ 01 ]
判断大端序和小端序
判断大端字节序还是小端字节序,只要看第一个地址中的值是高字节还是低字节。
代码来自参考文1,懒得写了哈。
#include <stdio.h> void endiannessOne(){ int a = 0x12345678; char *p = (char *)&a; if(*p == 0x12){ printf("%s this is big endian\n", __FUNCTION__); }else if(*p == 0x78){ printf("%s this is little endian\n", __FUNCTION__); }else{ printf("%s unable to determine endian\n", __FUNCTION__); } } void endiannessTwo(){ union test{ short a; char b; } c; c.a = 0x1234; if(c.b == 0x12){ printf("%s this is big endian\n", __FUNCTION__); }else if(c.b == 0x34){ printf("%s this is little endian\n", __FUNCTION__); }else{ printf("%s unable to determine endian\n", __FUNCTION__); } } int main(){ endiannessOne(); endiannessTwo(); return 0; }
使用场景
大端字节序
网络通信
在TCP / IP协议栈中,网络层和传输层的数据传输大多采用大端序。例如,IP地址和端口号在网络传输时,按照大端序进行编码。
原因是大端序在表示数字时更符合人类的阅读习惯,方便网络协议的设计者和开发者理解和处理数据。而且早期的网络设备和协议标准大多基于大端序,为了保持兼容性和一致性,后续的网络通信也延续了这种字节序。
某些编程语言和平台
Java虚拟机(JVM)采用大端序。在Java程序运行时,JVM将字节码加载到内存中,按照大端序来解析和执行字节码指令。
因为Java语言的设计初衷是跨平台,采用大端序可以更好地兼容不同平台的网络通信和数据存储格式。
小端字节序
流计算机架构
x86和x64架构的计算机(如常见的个人电脑和服务器)采用小端序。这是因为小端序在处理字节操作时比较方便。
例如,在进行内存操作时,如果要修改一个整数的某一个字节,小端序可以直接通过简单的地址偏移来访问和修改对应的字节。假设有一个32位整数存储在内存地址0x1000开始的位置,要修改它的最低字节,只需要访问内存地址0x1000即可,因为最低字节正好存储在低地址端。而在大端序中,可能需要先计算出要修改的字节所在的地址,相对复杂一些。
这种特性使得小端序在计算机内部的数据处理和内存管理方面具有一定的优势,能够提高计算机系统的整体性能。
嵌入式系统部分场景
虽然很多嵌入式系统采用大端序,但在一些特定的嵌入式场景下,小端序也有应用。例如,某些基于ARM架构的嵌入式设备(部分ARM架构也支持小端序模式),在进行一些对性能要求较高且主要在本地处理数据(不需要大量网络通信)的应用时,可能会采用小端序。
比如在一些工业控制设备中,主要进行本地的数据采集和处理,数据不需要频繁地在网络间传输。采用小端序可以更好地利用硬件的性能优势,提高数据处理速度。
参考文章
《》
《》
《
© 版权声明
